The following research is proudly supported by the National Science Foundation through the SaTC and CICI Programs (NSF Grants 2340949 and 2419880).
[Bio] Large Language Model for Bioinformatics and Health Science
We are developing a new graph model to analyze antimicrobial peptides and proteins (AMPs) and building an open-source dataset for AI training. Funded by the NSF Cybersecurity Innovation for Cyberinfrastructure (CICI) program, our project automates security assessments to protect data integrity from both accidental and malicious threats.
AMPs are essential for food safety, livestock health, and agricultural productivity, but traditional discovery methods are expensive and labor-intensive. AI and bioinformatics have boosted AMP research, yet large, unverified datasets pose cybersecurity risks if the data is altered or flawed. Our automated framework evaluates AMP sequences and functionality, reducing costly lab validations and promoting security awareness in the research community. It also creates an open-source dataset focused on AMP functionality security and offers an online platform for evaluation and security education.
Our work has two main goals: (1) filtering low-quality data with a model-driven approach and (2) exploring and defending against data poisoning vulnerabilities. By combining a novel graph model and an open-source dataset, we strengthen data integrity for AMP research and other peptide/protein studies. This effort bridges gaps in data security, fosters more reliable scientific collaborations, and provides an automated verification framework to broaden data access and innovation. Finally, the project emphasizes community engagement and cybersecurity education to advance health, prosperity, and welfare through scientific research.
Using AI and Molecular Modeling to Discover Better Bioactive Molecules
1. FusionESP: Predicting Which Molecules Enzymes Can Work With
Enzymes are nature’s tiny machines. They help living organisms carry out chemical reactions, such as breaking down food, building useful compounds, and supporting essential biological processes. However, figuring out which small molecules can be used by which enzymes often requires many expensive and time-consuming laboratory experiments.
In this study, the research team developed FusionESP, an artificial intelligence model that predicts whether a given enzyme and a small molecule are likely to form a true enzyme–substrate pair. The model combines information from two different “languages”: the amino acid sequence of the enzyme and the chemical structure of the molecule. By bringing protein knowledge and chemical knowledge into the same prediction framework, FusionESP can help researchers identify promising enzyme–molecule relationships more efficiently.
The best version of FusionESP achieved strong prediction performance and outperformed previous approaches on benchmark tests. This work provides a useful computational tool for accelerating research in biotechnology, food science, agriculture, and pharmaceutical discovery, where understanding enzyme activity is essential.
For more details, please refer to the paper:
Du, Zhenjiao, Weimin Fu, Xiaolong Guo, Doina Caragea, and Yonghui Li. "FusionESP: improved enzyme–substrate pair prediction by fusing protein and chemical knowledge." Journal of Chemical Information and Modeling 65, no. 6 (2025): 2806-2817.
2. Snakin-Z: Understanding How a Natural Plant Peptide Fights Microbes
Antibiotic resistance and food spoilage caused by microbes are growing challenges. Natural antimicrobial peptides, especially those derived from plants, are promising alternatives because they may help control harmful bacteria and fungi while reducing reliance on synthetic preservatives or conventional antibiotics.
This study focused on Snakin-Z, a small antimicrobial peptide found in Zizyphus jujuba fruit. Previous studies showed that Snakin-Z can inhibit bacteria and fungi while having very low damage to human red blood cells. The key question was: Why does Snakin-Z attack microbial membranes more strongly than human cell membranes?
Using detailed molecular dynamics simulations, the researchers studied how Snakin-Z interacts with model membranes representing bacteria, fungi, and red blood cells. The results showed that Snakin-Z binds more strongly to microbial membranes because they contain more negatively charged lipids. These lipids attract the positively charged parts of Snakin-Z, allowing the peptide to attach and disturb the membrane. In contrast, red blood cell membranes contain cholesterol, which helps keep the membrane stable and reduces Snakin-Z’s ability to disrupt it.
This work helps explain the molecular basis of Snakin-Z’s selectivity and supports its potential as a natural antimicrobial candidate for food preservation and biotechnology applications.
For more details, please refer to the paper:
Kumar, Nandan, Zhenjiao Du, Raghavendra G. Amachawadi, Xiaolong Guo, Jikai Zhao, and Yonghui Li. "Membrane selectivity mechanisms of the antimicrobial peptide Snakin-Z against prokaryotic and eukaryotic membrane models." The Journal of Physical Chemistry B 129, no. 18 (2025): 4392-4409.
3. PepBERT: A Lightweight AI Model Designed Specifically for Short Peptides
Bioactive peptides are short protein fragments that can have useful biological activities, such as antimicrobial, antioxidant, anticancer, or cell-penetrating functions. They are important for food science, nutrition, drug discovery, and biotechnology. However, discovering useful peptides is difficult because the number of possible peptide sequences is enormous.
Large protein language models have become powerful tools for analyzing biological sequences, but they are usually trained mostly on full-length proteins rather than short peptides. This can make them less efficient for peptide-specific tasks. To address this gap, the team developed PepBERT, a lightweight artificial intelligence model designed specifically for short peptide sequences.
PepBERT was trained on millions of peptide sequences and tested on nine different bioactive peptide prediction tasks. Despite being smaller than commonly used protein language models, PepBERT achieved comparable or better performance on most tasks. Its compact design also makes it easier and more efficient to use, especially for large-scale peptide screening.
This study provides a practical AI tool for accelerating the discovery of bioactive peptides, including food-derived peptides with potential health-promoting properties.
For more details, please refer to the paper:
Du, Zhenjiao, Doina Caragea, Xiaolong Guo, and Yonghui Li. "PepBERT: Lightweight language models for bioactive peptide representation." Future Foods (2026): 100999.
Together, these three studies show how artificial intelligence and molecular modeling can accelerate the discovery of useful biological molecules. PepBERT helps researchers better understand and represent short peptides. FusionESP helps predict how enzymes and small molecules may interact. The Snakin-Z study provides a detailed molecular explanation of how one promising antimicrobial peptide interacts with microbial and human-like membranes.
AI safety and security
1. Smarter Defenses Against LLM Jailbreaks
This paper introduces Dynamic Deep Prompt Optimization (DDPO), a lightweight defense that helps large language models resist jailbreak attacks. Instead of using a fixed safety prompt, DDPO creates a customized defensive signal for each user input by using the model’s own internal representations. This allows the model to better distinguish harmful requests from harmless but confusing ones. Experiments show that DDPO greatly reduces jailbreak success rates while preserving the model’s normal usefulness. This work offers a promising path toward safer AI systems without the cost of retraining the full model.
For more details, please refer to the paper:
Doniyorkhon Obidov, Honggang Yu, Xiaolong Guo, and Kaichen Yang, "Dynamic Deep Prompt Optimization for Defending Against Jailbreak Attacks on LLMs.'' The 40th Annual AAAI Conference on Artificial Intelligence (AAAI-26), January 20 - January 27, 2026, Singapore. [download]
2. Hidden Backdoors in LLM-Powered Robots
This paper reveals a new security risk in robots controlled by large language models. The authors show that a robot can be secretly programmed to misbehave when its own past actions match a hidden trigger sequence. Unlike traditional backdoors that rely on external words, objects, or scenes, this attack is triggered by the robot’s internal action history. In simulations with quadruped robots, the attack was highly successful while allowing the robot to behave normally when the trigger was absent. The study highlights the need to secure not only robot inputs, but also memory, action history, and hidden system instructions.
For more details, please refer to the paper:
Obidov, Doniyorkhon, Shivayogi Akki, Tan Chen, and Kaichen Yang. "Silent Sabotage: Internal State Triggered Backdoor Attacks on LLM-Powered Robotic Systems." (2026).
Together, these papers show two important directions in AI security: building stronger defenses for language models and uncovering hidden risks when LLMs are used in real-world robotic systems.
[Hardware] Attacking Edge LLM (New)


What It Is: A practical side-channel attack platform using 4 Raspberry Pi nodes with real-time power monitoring via USB-C meters. Perfect for exploring security weaknesses in LLM inference at the edge.
How It Works: We run quantized LLMs (less than 33B params) in distributed inference, while a host PC logs live power data from each board. Trace timing + power = insights into model structure, token processing, and hidden prompts.
Why It Matters: Understand and exploit timing and power-based leakage. Useful for offensive security research and defense strategies like power obfuscation, scheduling randomization, and model hardening.
This platform, built entirely from off-the-shelf components, empowers researchers, educators, and security enthusiasts to uncover and demonstrate real-world vulnerabilities in LLM deployments, without needing expensive lab equipment.
Demonstrated at:
Weimin Fu, Gang Qu, and Xiaolong Guo. A power side-channel attack platform for large language models on edge clusters. In NSF Workshop on Hardware Attack Artifacts, Analysis, and Metrics (WHAAAM) at DAC. ACM, 2025.
[Hardware] LLM Meets Hardware
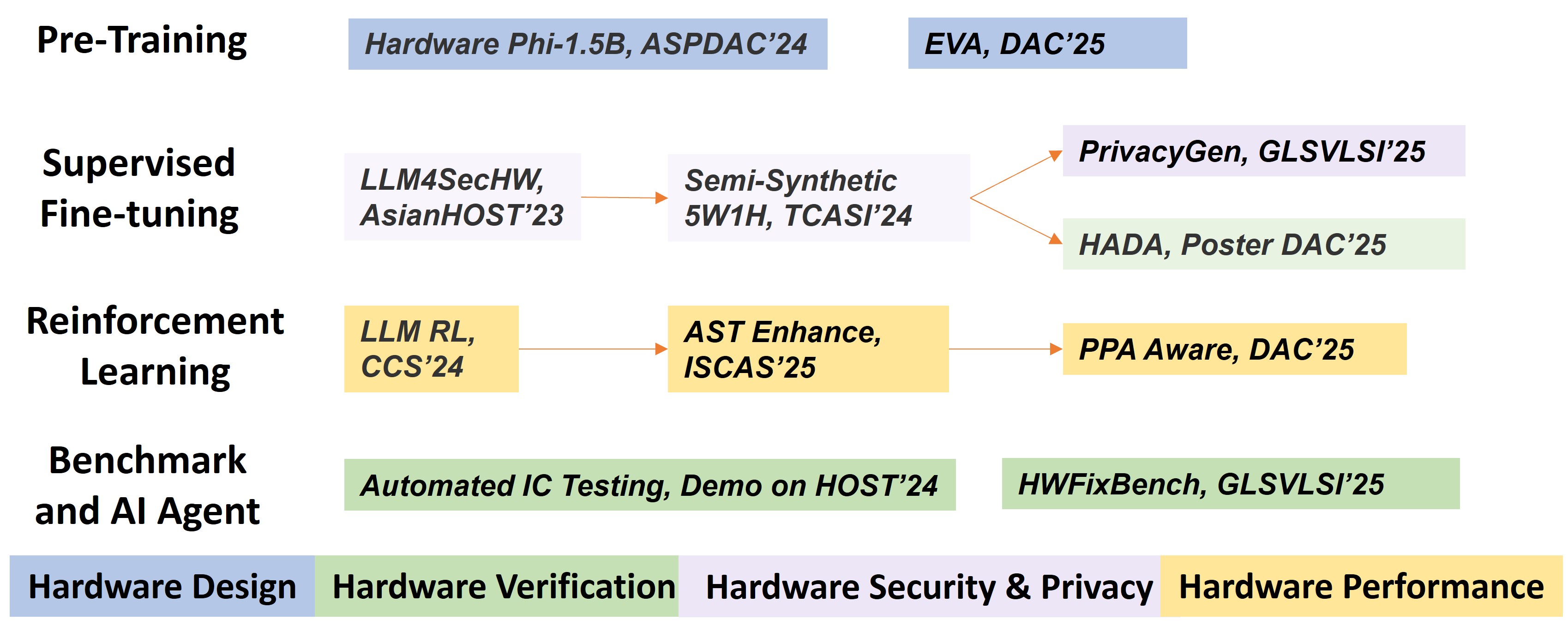
Fig. Overview of the LLM for hardware research in the lab.
[Hardware] Trustworthy LLM
Rethinking LLM Safety on Edge Devices: Vulnerabilities through Power Stress
The edge LLM safety must be evaluated as a hardware–software co-design problem, because on-device inference creates sustained compute/memory/I/O stress that can trigger silent data corruption (SDC) rather than obvious crashes. Using controlled undervolting on a Raspberry Pi 5 as a realistic, non-adversarial fault source, the authors compare two 1B instruction-tuned models (Gemma-3-1B-IT and LLaMA-3.2-1B) and measure layer-wise activation drift, decoding stability, and task-level accuracy; results show model-specific robustness (Gemma exhibits depth-amplified drift while LLaMA stays more numerically stable) and task-dependent degradation, where long, structured generation—especially code generation—is disproportionately vulnerable under voltage stress, motivating cross-stack reliability methods for future edge LLM deployments.
Our dataset is now officially available on Huggingface: TBD
For more details, please refer to our recently accepted paper:
Weimin Fu, Zelin Lu, Gang Qu, and Xiaolong Guo. "Rethinking LLM Safety on Edge Devices: Unearthing Hidden Vulnerabilities through Power Stress,'' IEEE Asian Hardware Oriented Security and Trust (AsianHOST), December 19-21, 2025 Nanjing, China. [download]
[Hardware] LLM Benchmarks
Fixbench-RTL: Benchmark for Evaluating LLMs on RTL Debugging
We present a novel benchmark specifically designed to evaluate LLMs on RTL debugging tasks. Each test case in our benchmark consists of four components: a buggy RTL code, its corresponding corrected version, a natural language description of the bug, and a simulation-based testbench for functional verification. The benchmark combines both synthetic and real-world errors, covering a wide spectrum of RTL errors, including syntax violations, functional bugs, and design vulnerabilities. Our benchmark enables more accurate and meaningful assessment of LLM-based debugging systems.
Our dataset is now officially available on Huggingface: https://huggingface.co/datasets/KSU-HW-SEC/Fixbench-RTL
For more details, please refer to our recently accepted work:
Shijie Li, Weimin Fu, Yifang Zhao, Xiaolong Guo, and Yier Jin. "Fixbench-RTL: A Comprehensive Benchmark for Evaluating LLMs on RTL Debugging,'' IEEE Asian Hardware Oriented Security and Trust (AsianHOST), December 19-21, 2025 Nanjing, China. [download]
HWFixBench
We constructed HWFixBench, a comprehensive benchmark derived from 500 pull requests and 1,481 bug fixes across 12 widely-used open-source hardware projects. HWFixBench reflects the challenges and complexity of real-world hardware tasks, providing a rigorous testbed for assessing whether LLMs can truly automate hardware development. We evaluate general-purpose LLMs, hardware-specialized LLMs, and prompt-based methods on HWFixBench, offering insights into their performance and limitations.
Our dataset is now officially available on Huggingface: https://huggingface.co/datasets/KSU-HW-SEC/issue_benchmark
For more details, please refer to our recently accepted work (GLSVLSI'25):
Weimin Fu, Shijie Li, Yier Jin, and Xiaolong Guo. "HWFixBench: Benchmarking Tools for Hardware Understanding and Fault Repair," ACM Great Lakes Symposium on VLSI (GLSVLSI) 2025. [download]
[Hardware] LLM Inferences and Agentic AI
Building Reasoning LLMs for Hardware Design Generation
Current LLM approaches for hardware generation typically focus on direct generation. This often results in hardware implementations with functional errors or structural flaws. To overcome these limitations, we propose a reasoning-enhanced training framework explicitly tailored for hardware generation tasks. Our multi-stage methodology combines systematic dataset curation via compilation filtering (achieving a 100% pass rate compared to 27-44% in existing datasets), Function-Aligned Differentiated Revision for comparative annotation across five RTL-relevant dimensions, supervised fine-tuning using reasoning prompts, and reinforcement learning guided by Verilator Parser. Our experiments show that explicitly incorporating reasoning substantially enhances the structural integrity and functional correctness of generated hardware designs, improving pass@1 rates by up to 20% on VerilogEval Human benchmarks and reproducing the "Aha moment", where the model explicitly organizes ideas before generation. Our work demonstrates that smaller, specialized reasoning models (1.5B parameters) can effectively augment larger open-source language models through reasoning transfer.
For more details, please refer to our recently accepted work:
Weimin Fu, Shijie Li, Yifang Zhao, Kaichen Yang, Xuan Zhang, Yier Jin and Xiaolong Guo, "Building Reasoning LLMs for Hardware Design Generation via Function-Aligned Differentiated Revision,'' The 2025 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), Oct 26-30, 2025, Munich, Germany. [download]
DDPO for Defending Against Jailbreak Attacks on LLMs
We propose Dynamic Deep Prompt Optimization (DDPO), the first jailbreak defense based on deep prompt optimization. DDPO uses the target LLM's own intermediate layers as feature extractors to dynamically generate defensive embeddings via a lightweight multilayer perceptron. These tailored embeddings are then injected into a subsequent intermediate layer, enabling an input-dependent defense without modifying the LLM's weights. This design ensures high adaptability with minimal computational overhead. Experiments on a diverse set of models and attacks demonstrate that DDPO significantly outperforms static prompt optimization methods, particularly on weakly aligned models and when handling semantically ambiguous benign prompts, successfully distinguishing them from genuinely harmful requests.
For more details, please refer to our recently accepted work:
Doniyorkhon Obidov, Honggang Yu, Xiaolong Guo, and Kaichen Yang, "Dynamic Deep Prompt Optimization for Defending Against Jailbreak Attacks on LLMs.'' The 40th Annual AAAI Conference on Artificial Intelligence (AAAI-26), January 20 - January 27, 2026, Singapore. [download]
Automated IC Testing
We constructed an automated integrated circuits (ICs) testing platform to demonstrate the potential applications of this LLM-based approach across the field. This platform takes the definitions of inputs and outputs from the IC's datasheet and the eval board as inputs, uses a meticulously designed experimental procedure, leverages decisions made by the PC and LLM to control the behavior of the instrumentation, and automatically provides evaluation results.
For more details, please refer to our recently accepted work (Demo at HOST'24):
Weimin Fu, Gang Qu, and Xiaolong Guo. "Large Language Model-Driven Real-World Applications: An Automated IC Testing System." in IEEE International Symposium on Hardware-Oriented Security and Trust (HOST), 2024. [download]
[Hardware] Pretraining Stage Work:
Hardware Phi-1.5B
First hardware domain-specific pretrained LLM in the World
We have conducted pretraining based on the Phi-1.5B model structure, making it more closely aligned with the needs of the hardware domain, enhancing the model's performance and stability in hardware design and verification tasks. It is the first pretrained hardware domain-specific LLM. Accordingly, we created three differently sized datasets rigorously screened and optimized them to guarantee content relevance and quality, thus laying a strong foundation for model training. The pre-trained model is offered openly to the community, thus supporting ongoing research, development, and innovation in both academic and industrial spheres. The releasing date will be around the presentation time of this paper in ASP-DAC 2024.
Our dataset is now officially available on Huggingface:
Large: https://huggingface.co/datasets/KSU-HW-SEC/hardware_code_and_sec_large
Median: https://huggingface.co/datasets/KSU-HW-SEC/hardware_code_and_sec_median
Small: https://huggingface.co/datasets/KSU-HW-SEC/hardware_code_and_sec_small
For more details, please refer to our recently accepted paper:
Weimin Fu, Shijie Li, Yifang Zhao, Haocheng Ma, Raj Dutta, Xuan Zhang, Kaicheng Yang, Yier Jin, and Xiaolong Guo. Hardware Phi-1.5B:A Large Language Model Encodes Hardware Domain Specific Knowledge. 29th IEEE/ACM Asia and South Pacific Design Automation Conference (ASP-DAC); 2024 January; Incheon Songdo Convensia, South Korea. [download]
[Hardware] Supervised Fine-tuning Stage Works:
LLM4SecHW
LLM4SecHW is an LLM-based hardware debugging framework designed to address the aforementioned issues. It aims to identify bugs and provide debugging suggestions during the hardware design iteration process. Specifically, we develop an innovative data collection and preprocessing method to harness version control information from open-source hardware projects. From this information, we construct a hardware debugging-oriented dataset by filtering and processing the version control data, which is subsequently utilized to fine-tune our model. Leveraging this dataset, we fine-tune a suite of hardware domain-specific language models capable of reading hardware designs and autonomously locating and rectifying bugs.
Our dataset, LLM4SecHW-OSHD, is now officially available on Huggingface: https://huggingface.co/datasets/KSU-HW-SEC/LLM4SecHW-OSHD
For more details, please refer to our recently accepted paper:
Weimin Fu, Kaichen Yang, Raj Gautam Dutta, Xiaolong Guo, and Gang Qu. Llm4sechw: Leavering domain-specific large language model for hardware debugging. Asian Hardware Oriented Security and Trust (AsianHOST), 2023. [download ]
Semi-Synthetic 5W1H
Integrating LLMs into the hardware debugging domain presents significant challenges due to the dual dilemma of data scarcity and subpar quality in hardware datasets. We proposed a directed, semi-synthetic data generation method that leverages version control information and journalistic event descriptions. This approach utilizes version control data from hardware projects combined with the 5W1H (Who, What, When, Where, Why, How) journalistic principles to produce high-quality data.
Our dataset is now officially available on Huggingface: https://huggingface.co/datasets/KSU-HW-SEC/5W1HHardwareDebug
For more details, please refer to our recently accepted paper:
Fu, Weimin, Shijie Li, Yifang Zhao, Kaichen Yang, Xuan Zhang, Yier Jin, and Xiaolong Guo. "A Generalize Hardware Debugging Approach for Large Language Models Semi-Synthetic, Datasets." IEEE Transactions on Circuits and Systems I: Regular Papers (2024). [download]
HADA
Traditional assertion generation relies heavily on engineers' expertise and manual effort. Formal verification and assertion generation methods are further limited by modeling complexity and a low tolerance for variations. We introduce a novel approach that fine-tunes a general-purpose LLM by leveraging its ability to integrate knowledge from multiple data sources. We combine assertions generated through formal verification, hardware security knowledge from datasets like the Common Weakness Enumeration (CWE), and version control data from hardware design iterations to construct a comprehensive hardware security assertion dataset.
Our dataset is now officially available on Huggingface: https://huggingface.co/datasets/KSU-HW-SEC/AssertionGen
For more details, please refer to our recently accepted poster (DAC'25):
Weimin Fu, Yiting Wang, Zelin Lu, Xiaolong Guo, and Gang Qu. "HADA: Leveraging Multi-Source Data to Train Large Language Models for Hardware Security Assertion Generation." IEEE Design Automation Conference (DAC) 2025. [download]
Intelligence In The Fence: PrivacyGen
This work proposes a localized, transparent, LLM-based solution PrivacyGen for automatic hardware design generation. The entire workflow does not rely on any commercial LLM and is executed in a local and completely controllable environment. It also contributes a new approach to generating high-quality datasets through the code explanation method. Through low-cost fine-tuning experiments, we construct a model with performance close to GPT-4 on complex designs of the RTLLM benchmark and better than GPT-4 on the VerilogEval benchmark. PrivacyGen will be open-sourced and our approach allows for generating your own dataset to construct an LLM solution under complete firewall protection and transparency.
Our dataset is now officially available on Huggingface: https://huggingface.co/datasets/KSU-HW-SEC/Verilog_code
For more details, please refer to our recently accepted work (GLSVLSI'25):
Shijie Li, Weimin Fu, Yifang Zhao, Xiaolong Guo, and Yier Jin. "Intelligence In The Fence: Construct A Privacy and Reliable Hardware Design Assistant LLM." ACM Great Lakes Symposium on VLSI (GLSVLSI) 2025, LA, USA. [download]
[Hardware] Reinforcement Learning Stage Works
LLM-RL
To enhance the performance of large language models (LLMs) on hardware design tasks, we focus on training with reinforcement learning(RL) to improve LLMs' syntax synthesis and functional verification performance. We observed significant gains in power, performance, and area (PPA) metrics by applying RL. Specifically, DeepSeek Code saw a 23.6% performance increase, while the RTLCoder improved by 7.86%. Our findings demonstrate the effectiveness of RL in refining LLMs for more accurate hardware generation, considering power and area consumption. This approach offers a promising direction for generating hardware resilient to side-channel attacks in computer systems.
Weimin Fu, Yifang Zhao, Yier Jin, and Xiaolong Guo, ``Poster: Enhance Hardware Domain Specific Large Language Model with Reinforcement Learning for Resilience,'' Proceedings of the 2024 ACM SIGSAC Conference on Computer and Communications Security (CCS '24), October 14--18, 2024, Salt Lake City, UT, USA. [download]
AST Enhance
In this work, we propose a novel LLM-based reinforcement learning (RL) framework that integrates Abstract Syntax Trees (ASTs) and Data Flow Graphs (DFGs). Our approach enhances the accuracy of generated hardware code by capturing the syntactic and semantic structures of hardware designs. The SFT-RL model integrated with Text, AST, and DFG achieves notable improvements: a 2.57% increase on VerilogEval-Human and a 5.49% increase on VerilogEval-Machine, outperforming GPT-4; a 14.29% improvement on RTLLM, approaching GPT-4’s performance. This breakthrough enables LLMs to overcome the challenges posed by the structural complexity of hardware descriptions, making them more practical for real-world hardware design tasks.
Our dataset is now officially available on Huggingface: https://huggingface.co/datasets/KSU-HW-SEC/Structure_data
For more details, please refer to our recently accepted work (ISCAS'25):
Yifang Zhao, Weimin Fu, Shijie Li, Yi-Xiang Hu, Xiaolong Guo and Yier Jin, ``Enhancing LLM Performance on Hardware Design Generation Task via Reinforcement Learning,'' 2025 IEEE International Symposium on Circuits and Systems, London, UK, May 25-28, 2025. [download]
PPA Aware
We propose an LLM-based reinforcement learning framework, PPA-RTL, aiming to introduce LLMs as a cutting-edge automation tool by directly incorporating post-synthesis metrics PPA into the hardware design generation phase. We design PPA metrics as reward feedback to guide the model in producing designs aligned with specific optimization objectives across various scenarios. In experimental evaluation, PPA-RTL demonstrates significant improvements compared to traditional LLM-based hardware design, providing a flexible framework for balancing performance, efficiency, and resource usage. Our work paves the way for more adaptive, efficient, cost-effective IC design automated processes.
Our dataset is now officially available on Huggingface: https://huggingface.co/datasets/KSU-HW-SEC/PPA_data
For more details, please refer to our recently accepted work (DAC'25):
Yifang Zhao, Weimin Fu, Shijie Li, Yi-Xiang Hu, Xiaolong Guo and Yier Jin, ``Hardware Generation with High Flexibility using Reinforcement Learning Enhanced LLMs,'' IEEE Design Automation Conference (DAC) 2025. [download]
The following research is proudly supported by the National Science Foundation through the S&CC Program (NSF Grant 2426890).
[Social Science] Large Language Model for Financial Exploitation
We use large language models (LLMs) to help older adults combat fraud and stay socially connected. Funded by NSF’s Smart and Connected Communities program, this project tackles financial exploitation among older adults.
Our smart assistive technology employs data-driven algorithms and generative AI to detect fraud, tracking all interactions from a soliciting party for comprehensive protection. We also consider social psychological factors—ergonomics, privacy, loneliness, attitudes toward technology, and fraud susceptibility.
This work helps product designers create practical solutions to prevent financial exploitation, improving older adults’ quality of life, independence, and reducing healthcare costs.
We tailor AI models for different user profiles (e.g., marital status, urban/rural, socio-economic status) and integrate email, social media, financial records, and phone calls. The proposed Large Multimodal Model (LMM) can process images and voices on users’ devices to protect privacy.
By examining fraudulent solicitations, social-emotional factors, and demographics, we aim to develop more targeted interventions to protect this vulnerable population.